Conway-Markdown (conwaymd, CMD) v6.0.0
Conway-Markdown is:
-
A replacement-driven markup language inspired by Markdown.
-
A demonstration of the folly of throwing regex at a parsing problem.
-
The result of someone joking that
the filenames would look like Windows executables from the 90s
.
-
Implemented in Python 3.{whatever Debian stable is at}.
-
Licensed under "MIT No Attribution" (MIT-0).
Contents
Installation
Conway-Markdown is published to PyPI as conwaymd:
$ pip3 install conwaymd
-
If simply using as a command line tool, do
pipx instead of pip3
to avoid having to set up a virtual environment.
-
If using Windows, do
pip instead of pip3.
Usage (command line)
$ cmd [-h] [-v] [-a] [-x] [file.cmd ...]
Convert Conway-Markdown (CMD) to HTML.
positional arguments:
file.cmd name of CMD file to be converted (can be abbreviated as
`file` or `file.` for increased productivity)
options:
-h, --help show this help message and exit
-v, --version show program's version number and exit
-a, --all convert all CMD files under the working directory
-x, --verbose run in verbose mode (prints every replacement applied)
On Windows:
-
Use the aliases
cmd- or conwaymd instead of cmd
to avoid summoning Command Prompt.
-
Beware not to run any
.cmd files by accident;
they might break your computer. God save!
Usage (scripting example)
Code:
from conwaymd.core import cmd_to_html
cmd_content = '''
# Test
==
- This is a *near*-minimal test.
- Here be [__dragons__].
==
[__dragons__]: https://example.com/
'''
html_content = cmd_to_html(cmd_content, cmd_file_name='scripting-test.py')
print(html_content)
Output:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="utf-8">
<meta name="viewport" content="width=device-width, initial-scale=1">
<title>Title</title>
</head>
<body>
<h1>Test</h1>
<ul>
<li>
This is a <em>near</em>-minimal test.
</li>
<li>
Here be <a href="https://example.com/"><b>dragons</b></a>.
</li>
</ul>
</body>
</html>
Authoring CMD files
CMD files are parsed thus:
«replacement rules»
«delimiter»
«main content»
-
«replacement rules» are user-defined CMD replacement rules
that will be used in addition to the standard CMD replacement rules.
-
«delimiter» is the first occurrence of
3-or-more percent signs on its own line.
(If no «delimiter» is found in the file,
the whole file is parsed as «main content».)
-
«main content» is the CMD content
that will be converted to HTML according to
the standard and user-defined CMD replacement rules.
In the implementation:
-
An empty replacement queue is initialised.
-
STANDARD_RULES in constants.py are parsed,
and CMD replacement rules are added to the replacement queue accordingly.
-
«replacement rules» in the CMD file are parsed,
and CMD replacement rules are added or inserted into the replacement queue
accordingly.
-
The CMD replacement rules in the replacement queue are
applied sequentially to
«main content»
to convert it to HTML.
To get started with writing «main content»,
read the listing of standard CMD replacement rules.
To learn about writing user-defined «replacement rules»,
read about CMD replacement rule syntax.
Standard CMD replacement rules
This section lists the standard CMD replacement rules
as defined by the constant string STANDARD_RULES in constants.py.
Some replacement rules are queued,
in that they appear explicitly in the replacement queue.
Other replacement rules are unqueued,
in that they do not appear explicitly in the replacement queue.
However, they might be called by queued replacements.
Standard queued replacements
0. #placeholder-markers
Definition
PlaceholderMarkerReplacement: #placeholder-markers
- queue_position: ROOT
Description
Replaces occurrences of the placeholder marker «U+F8FF»
with a placeholder
so that the occurrences will not be confounding.
1. #literals
Definition
ExtensibleFenceReplacement: #literals
- queue_position: AFTER #placeholder-markers
- syntax_type: INLINE
- allowed_flags:
u=KEEP_HTML_UNESCAPED
i=KEEP_INDENTED
w=REDUCE_WHITESPACE
- prologue_delimiter: <
- extensible_delimiter: `
- content_replacements:
#escape-html
#de-indent
#trim-whitespace
#reduce-whitespace
#placeholder-protect
- epilogue_delimiter: >
Syntax
<` «content» `>
«flags»<` «content» `>
-
«flags»:
-
The number of backticks
`
may be increased arbitrarily.
Description
Preserves «content» literally.
Examples
-
Write a literal string:
-
CMD:
<` <b>Foo</b> `>
-
HTML:
<b>Foo</b>
-
Rendered: <b>Foo</b>
-
Keep HTML unescaped:
-
CMD:
u<` <b>Foo</b> `>
-
HTML:
<b>Foo</b>
-
Rendered: Foo
-
Increase the number of backticks to include content
that matches the
#literals syntax itself:
-
CMD:
<`` Literally <`literal`>. ``>
-
HTML:
Literally <`literal`>.
-
Rendered: Literally <`literal`>.
2. #display-code
Definition
ExtensibleFenceReplacement: #display-code
- queue_position: AFTER #literals
- syntax_type: BLOCK
- allowed_flags:
u=KEEP_HTML_UNESCAPED
i=KEEP_INDENTED
w=REDUCE_WHITESPACE
- extensible_delimiter: ``
- attribute_specifications: EMPTY
- content_replacements:
#escape-html
#de-indent
#reduce-whitespace
#code-tag-wrap
#placeholder-protect
- tag_name: pre
Syntax
``
«content»
``
``{«attribute specifications»}
«content»
``
«flags»``
«content»
``
«flags»``{«attribute specifications»}
«content»
``
Description
Produces (pre-formatted) display code:
<pre«attribute sequence»><code>«content»
</code></pre>
Examples
-
Display code:
-
CMD:
``{.java}
for (int index = 0; index < count; index++)
{
// etc. etc.
}
``
-
HTML:
<pre class="java"><code>for (int index = 0; index < count; index++)
{
// etc. etc.
}
</code></pre>
-
Rendered:
for (int index = 0; index < count; index++)
{
// etc. etc.
}
-
Use
#literals with flag u to inject HTML:
-
CMD:
``
Injection of <b> element u<` <b>here</b> `>.
``
-
HTML:
<pre><code>Injection of <b> element <b>here</b>.
</code></pre>
-
Rendered:
Injection of <b> element here.
Definition
RegexDictionaryReplacement: #comments
- queue_position: AFTER #display-code
* [^\S\n]*
[<]
(?P<hashes> [#]+ )
[\s\S]*?
(?P=hashes)
[>]
-->
Syntax
<# «content» #>
-
The number of hashes
# may be increased arbitrarily.
Description
Remove CMD comments, along with all preceding whitespace.
Examples
-
#display-code prevails over #comments:
-
CMD:
``
Before.
<# This be a comment. #>
After.
``
-
HTML:
<pre><code>Before.
<# This be a comment. #>
After.
</code></pre>
-
Rendered:
Before.
<# This be a comment. #>
After.
-
#comments prevail over #inline-code:
-
CMD:
`Before. <# This be a comment. #> After.`
-
HTML:
<code>Before. After.</code>
-
Rendered:
Before. After.
-
Use
#literals to make #inline-code prevail over #comments:
-
CMD:
` <`Before. <# This be a comment. #> After.`> `
-
HTML:
<code>Before. <# This be a comment. #> After.</code>
-
Rendered:
Before. <# This be a comment. #> After.
4. #divisions
Definition
ExtensibleFenceReplacement: #divisions
- queue_position: AFTER #comments
- syntax_type: BLOCK
- extensible_delimiter: ||
- attribute_specifications: EMPTY
- content_replacements:
#divisions
#prepend-newline
- tag_name: div
Syntax
||
«content»
||
||{«attribute specifications»}
«content»
||
Description
Produces a division:
<div«attribute sequence»>
«content»
</div>
Examples
-
Division:
-
More pipes for nested divisions:
5. #blockquotes
Definition
ExtensibleFenceReplacement: #blockquotes
- queue_position: AFTER #divisions
- syntax_type: BLOCK
- extensible_delimiter: ""
- attribute_specifications: EMPTY
- content_replacements:
#blockquotes
#prepend-newline
- tag_name: blockquote
Syntax
""
«content»
""
""{«attribute specifications»}
«content»
""
Description
Produces a blockquote:
<blockquote«attribute sequence»>
«content»
</blockquote>
Examples
-
Blockquote:
6. #unordered-lists
Definition
ExtensibleFenceReplacement: #unordered-lists
- queue_position: AFTER #blockquotes
- syntax_type: BLOCK
- extensible_delimiter: ==
- attribute_specifications: EMPTY
- content_replacements:
#unordered-lists
#unordered-list-items
#prepend-newline
- tag_name: ul
Syntax
==
- «item»
«...»
==
=={«attribute specifications»}
-{«attribute specifications»} «item»
«...»
==
Description
Produces an unordered list:
<ul«attribute sequence»>
<li>
«item»
</li>
«...»
</ul>
Examples
-
Nested list:
7. #ordered-lists
Definition
ExtensibleFenceReplacement: #ordered-lists
- queue_position: AFTER #unordered-lists
- syntax_type: BLOCK
- extensible_delimiter: ++
- attribute_specifications: EMPTY
- content_replacements:
#ordered-lists
#ordered-list-items
#prepend-newline
- tag_name: ol
Syntax
++
1. «item»
«...»
++
++{«attribute specifications»}
1.{«attribute specifications»} «item»
«...»
++
Description
Produces an ordered list:
<ol«attribute sequence»>
<li>
«item»
</li>
«...»
</ol>
Examples
-
Any run of digits can be used in the item delimiter:
-
Nested ordered lists:
-
Zero-based indexing:
8. #tables
Definition
ExtensibleFenceReplacement: #tables
- queue_position: AFTER #ordered-lists
- syntax_type: BLOCK
- extensible_delimiter: ''
- attribute_specifications: EMPTY
- content_replacements:
#tables
#table-head
#table-body
#table-foot
#table-rows
#prepend-newline
- tag_name: table
Syntax
''
|^
//
; «item»
, «item»
«...»
«...»
|:
«...»
|_
«...»
''
''
//
; «item»
, «item»
«...»
«...»
''
''{«attribute specifications»}
|^{«attribute specifications»}
//{«attribute specifications»}
;{«attribute specifications»} «item»
,{«attribute specifications»} «item»
«...»
«...»
|:{«attribute specifications»}
«...»
|_{«attribute specifications»}
«...»
''
-
The number of single-quotes
'
may be increased arbitrarily.
-
Table parts:
-
Table cells:
-
«attribute specifications»:
see CMD attribute specifications.
Description
Produces a table:
<table«attribute sequence»>
«...»
</table>
Examples
-
Table without parts:
-
CMD:
''
//
; A
, 1
//
; B
, 2
''
-
HTML:
<table>
<tr>
<th>A</th>
<td>1</td>
</tr>
<tr>
<th>B</th>
<td>2</td>
</tr>
</table>
-
Rendered:
-
Table with head and body:
-
CMD:
''
|^
//
; A
; B
|:
//
, 1
, 2
//
, First
, Second
''
-
HTML:
<table>
<thead>
<tr>
<th>A</th>
<th>B</th>
</tr>
</thead>
<tbody>
<tr>
<td>1</td>
<td>2</td>
</tr>
<tr>
<td>First</td>
<td>Second</td>
</tr>
</tbody>
</table>
-
Rendered:
-
Cell merging
-
CMD:
''
//
,{c3} 3*1
, 14
//
, 21
, 22
, 23
, 24
//
,{rowspan=2 colspan="2"} 2*2
, 33
,{r2} 2*1
//
, 43
''
-
Rendered
| 3*1 |
14 |
| 21 |
22 |
23 |
24 |
| 2*2 |
33 |
2*1 |
| 43 |
9. #headings
Definition
HeadingReplacement: #headings
- queue_position: AFTER #tables
- attribute_specifications: EMPTY
Syntax
# «content»
#{«attribute specifications»} «content»
-
The number of hashes
# may be between 1 and 6.
-
«content» may be optionally closed by hashes.
-
For continuation of
«content»,
indent the continuation more than the leading hashes.
-
«attribute specifications»:
see CMD attribute specifications.
Description
Produces a heading:
<h«hash count»>«content»</h«hash count»>
Examples
-
Empty headings:
-
Non-empty headings require whitespace after the hashes:
-
Optional closing hashes:
-
Continuation:
-
CMD:
##{.interesting-heading-class}
This heading is so long, I have used continuation.
Second continuation line.
This line is not a continuation due to insufficient indentation.
-
HTML:
<h2 class="interesting-heading-class">
This heading is so long, I have used continuation.
Second continuation line.</h2>
This line is not a continuation due to insufficient indentation.
10. #paragraphs
Definition
ExtensibleFenceReplacement: #paragraphs
- queue_position: AFTER #headings
- syntax_type: BLOCK
- extensible_delimiter: --
- attribute_specifications: EMPTY
- prohibited_content: BLOCKS
- content_replacements:
#prepend-newline
- tag_name: p
Syntax
--
«content»
--
--{«attribute specifications»}
«content»
--
Description
Produces a paragraph:
<p«attribute sequence»>
«content»
</p>
Examples
-
Paragraph:
-
CMD:
--
The quick brown fox etc. etc.
--
-
HTML:
<p>
The quick brown fox etc. etc.
</p>
-
Rendered:
The quick brown fox etc. etc.
-
Paragraphs cannot be nested:
-
CMD:
----
Before.
--
Not a nested paragraph.
--
After.
----
-
HTML:
<p>
Before.
--
Not a nested paragraph.
--
After.
</p>
-
Rendered:
Before.
--
Not a nested paragraph.
--
After.
11. #inline-code
Definition
ExtensibleFenceReplacement: #inline-code
- queue_position: AFTER #paragraphs
- syntax_type: INLINE
- allowed_flags:
u=KEEP_HTML_UNESCAPED
i=KEEP_INDENTED
w=REDUCE_WHITESPACE
- extensible_delimiter: `
- attribute_specifications: EMPTY
- prohibited_content: ANCHORED_BLOCKS
- content_replacements:
#escape-html
#de-indent
#trim-whitespace
#reduce-whitespace
#placeholder-protect
- tag_name: code
Syntax
` «content» `
`{«attribute specifications»} «content» `
«flags»` «content» `
«flags»`{«attribute specifications»} «content» `
Description
Produces inline code:
<code«attribute sequence»>«content»</code>
Examples
-
Code:
-
CMD:
`<br>`
-
HTML:
<code><br></code>
-
Rendered:
<br>
-
Code containing backticks:
-
CMD:
``A `backticked` word.``
-
HTML:
<code>A `backticked` word.</code>
-
Rendered:
A `backticked` word.
-
Use
#literals with flag u to inject HTML:
-
CMD:
`Some u<`<b>bold</b>`> code`
-
HTML:
<code>Some <b>bold</b> code</code>
-
Rendered:
Some bold code
12. #boilerplate
Definition
RegexDictionaryReplacement: #boilerplate
- queue_position: AFTER #inline-code
* \A -->
<!DOCTYPE html>
<html lang="%lang">
<head>
<meta charset="utf-8">
%head-elements-before-viewport
<meta name="viewport" content="%viewport-content">
%head-elements-after-viewport
<title>%title</title>
<style>
%styles
</style>
</head>
<body>\n
* \Z -->
</body>
</html>\n
Description
Wraps content in the HTML5 boilerplate:
-
<!DOCTYPE html> through <body> at the start
-
</body></html> at the end
The default boilerplate properties
%lang,
%head-elements-before-viewport,
%viewport-content,
%head-elements-after-viewport,
%title, and
%styles
are set in #boilerplate-properties.
13. #boilerplate-properties
Definition
OrdinaryDictionaryReplacement: #boilerplate-properties
- queue_position: AFTER #boilerplate
* %lang --> en
* %head-elements-before-viewport -->
* %viewport-content --> width=device-width, initial-scale=1
* %head-elements-after-viewport -->
* %title --> Title
* %styles -->
Description
Makes replacements for the default boilerplate properties:
| Property |
Default value |
%lang |
en |
%head-elements-before-viewport |
(empty) |
%viewport-content |
width=device-width, initial-scale=1 |
%head-elements-after-viewport |
(empty) |
%title |
Title |
%styles |
(empty) |
Examples
-
Defaults:
-
CMD:
# %title
This document hath `lang` equal to <code>%lang</code>.
-
HTML (including boilerplate):
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="utf-8">
<meta name="viewport" content="width=device-width, initial-scale=1">
<title>Title</title>
</head>
<body>
<h1>Title</h1>
This document hath <code>lang</code> equal to <code>en</code>.
</body>
</html>
-
Override the defaults:
-
CMD:
OrdinaryDictionaryReplacement: #.boilerplate-properties-override
- queue_position: BEFORE #boilerplate-properties
* %lang --> en-AU
* %head-elements-before-viewport --> <meta name="author" content="Me">
* %title --> Overridden title
%%%
# %title
This document hath `lang` equal to <code>%lang</code>.
-
HTML (including boilerplate):
<!DOCTYPE html>
<html lang="en-AU">
<head>
<meta charset="utf-8">
<meta name="author" content="Me">
<meta name="viewport" content="width=device-width, initial-scale=1">
<title>Overridden title</title>
</head>
<body>
<h1>Overridden title</h1>
This document hath <code>lang</code> equal to <code>en-AU</code>.
</body>
</html>
14. #cmd-properties
Definition
OrdinaryDictionaryReplacement: #cmd-properties
- queue_position: AFTER #boilerplate-properties
* %cmd-version --> {CMD_VERSION}
* %cmd-name --> {CMD_NAME}
* %cmd-basename --> {CMD_BASENAME}
* %clean-url --> {CLEAN_URL}
- concluding_replacements:
#placeholder-protect
Description
Makes replacements for CMD properties:
| Property |
Description |
%cmd-version |
__version__ in _version.py
(currently 6.0.0) |
%cmd-name |
CMD file name, relative to working directory, without extension |
%cmd-basename |
CMD file name, without path, without extension |
%clean-url |
%cmd-name,
with %cmd-basename removed if it equals index |
15. #boilerplate-protect
Definition
RegexDictionaryReplacement: #boilerplate-protect
- queue_position: AFTER #cmd-properties
* <style>[\s]*?</style>[\s]* -->
* <style>[\s\S]*?</style> --> \g<0>
* <head>[\s\S]*?</head> --> \g<0>
- concluding_replacements:
#reduce-whitespace
#placeholder-protect
Description
Protects boilerplate elements:
-
Removes empty
<style> element
-
Protects
<style> element
-
Protects
<head> element
16. #backslash-escapes
Definition
OrdinaryDictionaryReplacement: #backslash-escapes
- queue_position: AFTER #boilerplate-protect
* \\ --> \
* \" --> "
* \# --> #
* \& --> &
* \' --> '
* \( --> (
* \) --> )
* \* --> *
* \< --> <
* \> --> >
* \[ --> [
* \] --> ]
* \_ --> _
* \{ --> {
* \| --> |
* \} --> }
* "\ " --> " "
* \t --> " "
- concluding_replacements:
#placeholder-protect
Description
Applies backslash escapes:
| Escaped |
Unescaped |
\\ |
\ |
\" |
" |
\# |
# |
\& |
& |
\' |
' |
\( |
( |
\) |
) |
\* |
* |
\< |
< |
\> |
> |
\[ |
[ |
\] |
] |
\_ |
_ |
\{ |
{ |
\| |
| |
\} |
} |
\ |
(space) |
\t |
(tab) |
17. #backslash-continuations
Definition
RegexDictionaryReplacement: #backslash-continuations
- queue_position: AFTER #backslash-escapes
* \\ \n [^\S\n]* -->
Description
Applies backslash continuation.
18. #reference-definitions
Definition
ReferenceDefinitionReplacement: #reference-definitions
- queue_position: AFTER #backslash-continuations
- attribute_specifications: EMPTY
Syntax
[«label»]: «uri»
[«label»]: <«uri»>
[«label»]: «...» "«title»"
[«label»]: «...» '«title»'
[«label»]{«attribute specifications»}: «...»
-
For continuation of
«uri» or «title»,
indent the continuation more than the leading square bracket.
-
«attribute specifications»:
see CMD attribute specifications.
Description
Defines a reference, to be used by
#referenced-images or #referenced-links.
19. #specified-images
Definition
SpecifiedImageReplacement: #specified-images
- queue_position: AFTER #reference-definitions
- attribute_specifications: EMPTY
- prohibited_content: BLOCKS
Syntax




![«alt text»]{«attribute specifications»}(«...»)
Description
Produces an image:
<img«attribute sequence»>
Here, «attribute sequence» is the sequence of attributes
built from
-
«alt text»
-
«src»
-
«title»
-
«attribute specifications»
parsed in that order.
Examples
-
Basic usage:
-
Set width:
-
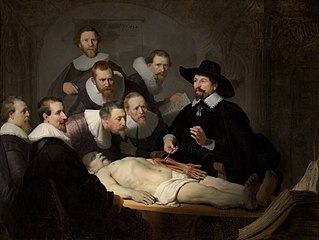
CMD:
![Rembrandt painting: The Anatomy Lesson of Dr Nicolaes Tulp.]{w=120}(rembrandt-anatomy.jpg)
-
HTML:
<img alt="Rembrandt painting: The Anatomy Lesson of Dr Nicolaes Tulp." src="rembrandt-anatomy.jpg" width="120">
-
Rendered:
-
Empty alt text for decorative images,
or images where adjacent text already describes the image:
20. #referenced-images
Definition
ReferencedImageReplacement: #referenced-images
- queue_position: AFTER #specified-images
- attribute_specifications: EMPTY
- prohibited_content: BLOCKS
Syntax
![«alt text»][«label»]
![«alt text»]
![«alt text»]{«attribute specifications»}[«label»]
![«alt text»]{«attribute specifications»}
Description
Produces an image:
<img«attribute sequence»>
Here, «attribute sequence» is the sequence of attributes
built from
parsed in that order.
Examples
-
Basic usage:
-
Use
«alt text» for «label»:
-
«label» is case-insensitive:
-
CMD:
[image-label-case]: insensitive.png
[Hooray.][image-label-case]
[Hooray.][image-label-CASE]
[Hooray.][ImAGe-laBEl-CAsE]
-
HTML:
<a href="insensitive.png">Hooray.</a>
<a href="insensitive.png">Hooray.</a>
<a href="insensitive.png">Hooray.</a>
-
Later reference definitions prevail:
21. #explicit-links
Definition
ExplicitLinkReplacement: #explicit-links
- queue_position: AFTER #referenced-images
- allowed_flags:
b=ANGLE_BRACKET_WRAP
s=SUPPRESS_SCHEME
- attribute_specifications: EMPTY
- content_replacements:
#suppress-scheme
- concluding_replacements:
#angle-bracket-wrap
Syntax
<«uri»>
<{«attribute specifications»} «uri»>
«flags»<«uri»>
«flags»<{«attribute specifications»} «uri»>
Description
Produces a link:
<a«attribute sequence»>«uri»</a>
Or:
<<a«attribute sequence»>«uri»</a>>
Here, «attribute sequence» is the sequence of attributes
built from
-
«uri» as href
-
«attribute specifications»
parsed in that order.
Examples
-
Basic usage:
-
CMD:
<https://example.com>
-
HTML:
<a href="https://example.com">https://example.com</a>
-
Rendered: https://example.com
-
Wrap in angle brackets:
-
CMD:
b<https://example.com>
-
HTML:
<<a href="https://example.com">https://example.com</a>>
-
Rendered: <https://example.com>
-
Suppress scheme:
-
CMD:
s<https://example.com>
-
HTML:
<a href="https://example.com">example.com</a>
-
Rendered: example.com
-
¿Por qué no los dos?
-
CMD:
bs<https://example.com>
-
HTML:
<<a href="https://example.com">example.com</a>>
-
Rendered: <example.com>
-
Invitation to spammers:
-
CMD:
s<mailto:mail@example.com>
-
HTML:
<a href="mailto:mail@example.com">mail@example.com</a>
-
Rendered: mail@example.com
22. #specified-links
Definition
SpecifiedLinkReplacement: #specified-links
- queue_position: AFTER #explicit-links
- attribute_specifications: EMPTY
- prohibited_content: BLOCKS
Syntax
[«link text»](«href»)
[«link text»](<«href»>)
[«link text»](«...» "«title»")
[«link text»](«...» '«title»')
[«link text»]{«attribute specifications»}(«...»)
Description
Produces a link:
<a«attribute sequence»>«link text»</a>
Here, «attribute sequence» is the sequence of attributes
built from
-
«href»
-
«title»
-
«attribute specifications»
parsed in that order.
Examples
-
Basic usage:
-
Title:
-
CMD:
[Wikipedia](
https://en.wikipedia.org/wiki/Main_Page
"Wikipedia, the free encyclopedia"
)
-
HTML:
<a href="https://en.wikipedia.org/wiki/Main_Page" title="Wikipedia, the free encyclopedia">Wikipedia</a>
-
Rendered:
Wikipedia
-
Override
href
23. #referenced-links
Definition
ReferencedLinkReplacement: #referenced-links
- queue_position: AFTER #specified-links
- attribute_specifications: EMPTY
- prohibited_content: BLOCKS
Syntax
[«link text»][«label»]
[«link text»]
[«link text»]{«attribute specifications»}[«label»]
[«link text»]{«attribute specifications»}
Description
Produces a link:
<a«attribute sequence»>«link text»</a>
Here, «attribute sequence» is the sequence of attributes
built from
parsed in that order.
Examples
-
Basic usage:
-
Use
«link text» for «label»:
-
«label» is case-insensitive:
-
CMD:
[link-label-case]: https://example.com
[Hooray.][link-label-case]
[Hooray.][link-label-CASE]
[Hooray.][LiNK-laBEl-CAsE]
-
HTML:
<a href="https://example.com">Hooray.</a>
<a href="https://example.com">Hooray.</a>
<a href="https://example.com">Hooray.</a>
-
Later reference definitions prevail:
-
CMD:
[link-label]{.class1}: https://example.com/1
[link-label]{.class2}: https://example.com/2
[Second definition wins.][link-label]
-
HTML:
<a href="https://example.com/2" class="class2">Second definition wins.</a>
24. #inline-semantics
Definition
InlineAssortedDelimitersReplacement: #inline-semantics
- queue_position: AFTER #referenced-links
- delimiter_conversion:
__=b
_=i
**=strong
*=em
''=cite
""=q
- attribute_specifications: EMPTY
- prohibited_content: BLOCKS
Syntax
__«b content»__
_«i content»_
**«strong content»**
*«em content»*
''«cite content»''
""«q content»""
«...»{«attribute specifications»} «content»«...»
|«...»«content»«...»
|«...»{«attribute specifications»} «content»«...»
-
«attribute specifications»:
see CMD attribute specifications.
-
The leading optional pipe is to be used
as a disambiguator in some edge cases.
If present, it indicates that the delimiter directly after it
is opening rather than closing.
-
The opening delimiter must not be followed by whitespace,
nor by
</ (the beginning of a closing tag).
-
The closing delimiter must not be preceded by whitespace,
nor by a pipe
|.
Description
Produces an inline semantic:
<b«attribute sequence»>«b content»</b>
<i«attribute sequence»>«i content»</i>
<strong«attribute sequence»>«strong content»</strong>
<em«attribute sequence»>«em content»</em>
<cite«attribute sequence»>«cite content»</cite>
<q«attribute sequence»>«q content»</q>
Examples
In HTML5, <b> and <i> are not deprecated,
see W3C: Using <b> and <i> elements.
-
Bring to attention
<b>:
-
Keywords:
-
CMD:
Meals are served with __rice__ or __pasta__.
-
HTML:
Meals are served with <b>rice</b> or <b>pasta</b>.
-
Rendered: Meals are served with rice or pasta.
-
Idiomatic offset
<i>:
-
Foreign phrases:
-
CMD:
Write out _{lang=la} Romani ite domum_ 100 times.
-
HTML:
Write out <i lang="la">Romani ite domum</i> 100 times.
-
Rendered: Write out Romani ite domum 100 times.
-
Translator-supplied words in the King James Bible:
-
CMD:
I _{.translator-supplied} am_ the LORD.
-
HTML:
I <i class="translator-supplied">am</i> the LORD.
-
Rendered: I am the LORD.
-
Thoughts:
-
CMD:
_Screw 'em._
-
HTML:
<i>Screw 'em.</i>
-
Rendered: Screw 'em.
-
Strong importance
<strong>:
-
Warnings:
-
CMD:
**{lang=de} Achtung!**
-
HTML:
<strong lang="de">Achtung!</strong>
-
Rendered: Achtung!
-
Stress emphasis
<em>:
-
Stress a particular word in a sentence:
-
CMD:
I don't know *who* took it.
-
HTML:
I don't know <em>who</em> took it.
-
Rendered: I don't know who took it.
-
Citation
<cite>:
-
Book titles:
-
CMD:
''Nineteen Eighty-Four'' is already upon us.
-
HTML:
<cite>Nineteen Eighty-Four</cite> is already upon us.
-
Rendered: Nineteen Eighty-Four is already upon us.
-
Quotation
<q>:
-
Inline quotes:
-
CMD:
""It wasn't me.""
-
HTML:
<q>It wasn't me.</q>
-
Rendered:
It wasn't me.
-
Nesting and disambiguation:
| Pattern |
CMD |
HTML |
| 1-1 |
*foo* |
<em>foo</em> |
| 2-2 |
**foo** |
<strong>foo</strong> |
| 3-3 (12-21) |
***foo*** |
<em><strong>foo</strong></em> |
| 12-3 (12-21) |
*foo **bar*** |
<em>foo <strong>bar</strong></em> |
| 3-21 (12-21) |
***foo** bar* |
<em><strong>foo</strong> bar</em> |
| 2|1-3 (21-12) |
**|*foo*** |
<strong><em>foo</em></strong> |
| 21-3 (21-12) |
**foo *bar*** |
<strong>foo <em>bar</em></strong> |
| 3-12 (21-12) |
***foo* bar** |
<strong><em>foo</em> bar</strong> |
| 4-4 (22-22) |
****foo**** |
<strong><strong>foo</strong></strong> |
| 1|2|1-4 (121-121) |
*|**|*foo**** |
<em><strong><em>foo</em></strong></em> |
25. #escape-idle-html
Definition
RegexDictionaryReplacement: #escape-idle-html
- queue_position: AFTER #inline-semantics
* [&]
(?!
(?:
[a-zA-Z]{1,31}
|
[#] (?: [0-9]{1,7} | [xX] [0-9a-fA-F]{1,6} )
)
[;]
)
--> &
* [<] (?= [\s] ) --> <
Description
Escapes idle HTML:
-
Replaces non-entity ampersand with
&.
-
Replaces opening angle brackets before whitespace with
<
26. #whitespace
Definition
ReplacementSequence: #whitespace
- queue_position: AFTER #escape-idle-html
- replacements:
#reduce-whitespace
Description
Reduces whitespace. See #reduce-whitespace.
27. #placeholder-unprotect
Definition
PlaceholderUnprotectionReplacement: #placeholder-unprotect
- queue_position: AFTER #whitespace
Description
Unprotects all placeholder strings.
Standard unqueued replacements
#placeholder-protect
Definition
PlaceholderProtectionReplacement: #placeholder-protect
Description
Protects a string with a placeholder.
Dependants
#de-indent
Definition
DeIndentationReplacement: #de-indent
- negative_flag: KEEP_INDENTED
Description
Removes the longest common indentation in a string.
Dependants
#escape-html
Definition
OrdinaryDictionaryReplacement: #escape-html
- negative_flag: KEEP_HTML_UNESCAPED
* & --> &
* < --> <
* > --> >
Description
Escapes &, <, and > as their respective HTML ampersand entities.
Dependants
#trim-whitespace
Definition
RegexDictionaryReplacement: #trim-whitespace
* \A [\s]* -->
* [\s]* \Z -->
Description
Removes whitespace at the very start and very end of the string.
Dependants
#reduce-whitespace
Definition
RegexDictionaryReplacement: #reduce-whitespace
- positive_flag: REDUCE_WHITESPACE
* ^ [^\S\n]+ -->
* [^\S\n]+ $ -->
* [\s]+ (?= <br> ) -->
* [\n]+ --> \n
Description
-
Removes leading horizontal whitespace on each line.
-
Removes trailing horizontal whitespace on each line.
-
Removes whitespace before
<br>.
-
Collapsed multiple consecutive newlines into a single newline.
Dependants
#code-tag-wrap
Definition
RegexDictionaryReplacement: #code-tag-wrap
* \A --> <code>
* \Z --> </code>
Description
Wraps a string in opening and closing code tags.
Dependants
#prepend-newline
Definition
RegexDictionaryReplacement: #prepend-newline
* \A --> \n
Description
Adds a newline at the very start of a string.
Dependants
#unordered-list-items
Definition
PartitioningReplacement: #unordered-list-items
- starting_pattern: [-+*]
- attribute_specifications: EMPTY
- content_replacements:
#prepend-newline
- ending_pattern: [-+*]
- tag_name: li
Description
Partitions content into list items based on leading occurrences of
-, +, or *.
Dependants
#ordered-list-items
Definition
PartitioningReplacement: #ordered-list-items
- starting_pattern: [0-9]+ [.]
- attribute_specifications: EMPTY
- content_replacements:
#prepend-newline
- ending_pattern: [0-9]+ [.]
- tag_name: li
Description
Partitions content into list items based on leading occurrences of
a run of digits followed by a full stop.
Dependants
Definition
RegexDictionaryReplacement: #mark-table-headers-for-preceding-table-data
* \A --> ;{}
# Replaces `<th«attributes_sequence»>` with `;{}<th«attributes_sequence»>`,
# so that #table-data will know to stop before it.
Description
Replaces <th«attributes_sequence»>
with ;{}<th«attributes_sequence»>
so that #table-data will know to stop before it.
Dependants
Definition
PartitioningReplacement: #table-headers
- starting_pattern: [;]
- attribute_specifications: EMPTY
- content_replacements:
#trim-whitespace
- ending_pattern: [;,]
- tag_name: th
- concluding_replacements:
#mark-table-headers-for-preceding-table-data
Description
Partitions content into table headers
based on leading occurrences of ;
up to the next leading ; or ,.
Dependants
#table-data
Definition
PartitioningReplacement: #table-data
- starting_pattern: [,]
- attribute_specifications: EMPTY
- content_replacements:
#trim-whitespace
- ending_pattern: [;,]
- tag_name: td
Description
Partitions content into table data
based on leading occurrences of ,
up to the next leading ; or ,.
Dependants
Definition
RegexDictionaryReplacement: #unmark-table-headers-for-preceding-table-data
* ^ [;] \{ \} <th (?P<bracket_or_placeholder_marker> [>\uF8FF] )
-->
<th\g<bracket_or_placeholder_marker>
# Replaces `;{}<th«attributes_sequence»>` with `<th«attributes_sequence»>`
# so that #mark-table-headers-for-preceding-table-data is undone.
Description
Replaces ;{}<th«attributes_sequence»>
with <th«attributes_sequence»>
so that #mark-table-headers-for-preceding-table-data is undone.
Dependants
#table-rows
Definition
PartitioningReplacement: #table-rows
- starting_pattern: [/]{2}
- attribute_specifications: EMPTY
- ending_pattern: [/]{2}
- content_replacements:
#table-headers
#table-data
#unmark-table-headers-for-preceding-table-data
#prepend-newline
- tag_name: tr
Description
Partitions content into table rows
based on leading occurrences of //.
Dependants
#table-head
Definition
PartitioningReplacement: #table-head
- starting_pattern: [|][\^]
- attribute_specifications: EMPTY
- ending_pattern: [|][:_]
- content_replacements:
#table-rows
#prepend-newline
- tag_name: thead
Description
Partitions content into table heads
based on leading occurrences of |^
up to the next leading |: or |_.
Dependants
#table-body
Definition
PartitioningReplacement: #table-body
- starting_pattern: [|][:]
- attribute_specifications: EMPTY
- ending_pattern: [|][_]
- content_replacements:
#table-rows
#prepend-newline
- tag_name: tbody
Description
Partitions content into table bodies
based on leading occurrences of |:
up to the next leading |_.
Dependants
Definition
PartitioningReplacement: #table-foot
- starting_pattern: [|][_]
- attribute_specifications: EMPTY
- content_replacements:
#table-rows
#prepend-newline
- tag_name: tfoot
Description
Partitions content into table feet
based on leading occurrences of |_.
Dependants
#suppress-scheme
Definition
RegexDictionaryReplacement: #suppress-scheme
- positive_flag: SUPPRESS_SCHEME
* \A [\S]+ [:] (?: [/]{2} )? -->
Description
Suppresses the scheme
(including the colon and possibly two slashes)
of a URI.
Dependants
#angle-bracket-wrap
Definition
RegexDictionaryReplacement: #angle-bracket-wrap
- positive_flag: ANGLE_BRACKET_WRAP
* \A --> <
* \Z --> >
- concluding_replacements:
#placeholder-protect
Description
Wraps a string in angle brackets.
Dependants
CMD replacement rule syntax
This section gives the syntax for writing user-defined CMD replacement rules,
which go before the «delimiter» when authoring CMD files.
In CMD replacement rule syntax, a line must be one of the following:
-
Whitespace-only.
Ends the definition of a replacement rule.
-
A comment:
# «comment»
Is ignored.
-
A rules inclusion:
< «included_file_name»
Includes the content of «included_file_name»
as CMD replacement rules.
-
If
«included_file_name» begins with a slash,
it is parsed relative to the working directory.
-
If
«included_file_name» does not begin with a slash,
it is parsed relative to the file in which the inclusion is invoked.
The convention is for «included_file_name»
to have the extension .cmdr.
-
A class declaration:
«ClassName»: #«id»
Begins the definition of a replacement rule
with class «ClassName».
-
«ClassName» must be one of
ReplacementSequence,
PlaceholderMarkerReplacement,
PlaceholderProtectionReplacement,
PlaceholderUnprotectionReplacement,
DeIndentationReplacement,
OrdinaryDictionaryReplacement,
RegexDictionaryReplacement,
FixedDelimitersReplacement,
ExtensibleFenceReplacement,
PartitioningReplacement,
InlineAssortedDelimitersReplacement,
HeadingReplacement,
ReferenceDefinitionReplacement,
SpecifiedImageReplacement,
ReferencedImageReplacement,
ExplicitLinkReplacement,
SpecifiedLinkReplacement,
or
ReferencedLinkReplacement.
-
«id» may only contain
lower-case letters, digits, hyphens, and full stops.
The convention is for user-defined replacement rules
to have «id» beginning with a full stop
(whereas the standard rules
have «id» beginning with a letter or digit).
-
The start of an attribute declaration:
- «name»: «value»
Declares an attribute for the replacement that is currently being defined.
-
«name» must be one of the valid attribute names
for the replacement that is currently being defined.
-
«value» must be a suitable attribute value
for that attribute name.
-
The start of an substitution declaration:
* «pattern» --> «substitute»
Declares a substitution for the replacement that is currently being defined
(which must be an OrdinaryDictionaryReplacement
or a RegexDictionaryReplacement).
-
The number of hyphens in the delimiter
-->
may be arbitrarily increased should «pattern» contain
a run of hyphens followed by a closing angle-bracket.
-
A continuation (of an attribute declaration or substitution declaration),
beginning with whitespace.
ReplacementSequence
Syntax
ReplacementSequence: #«id»
- queue_position: (def) NONE | ROOT | BEFORE #«id» | AFTER #«id»
- replacements: (def) NONE | #«id» [...]
-
queue_position:
position in the replacement queue
-
replacements:
sequence of replacements to be applied
Description
Defines a replacement rule that applies a sequence of replacement rules.
Standard rules usage
PlaceholderMarkerReplacement
Syntax
PlaceholderMarkerReplacement: #«id»
- queue_position: (def) NONE | ROOT | BEFORE #«id» | AFTER #«id»
-
queue_position:
position in the replacement queue
Description
Defines a rule for replacing the placeholder marker with a placeholder.
Standard rules usage
PlaceholderProtectionReplacement
Syntax
PlaceholderProtectionReplacement: #«id»
- queue_position: (def) NONE | ROOT | BEFORE #«id» | AFTER #«id»
-
queue_position:
position in the replacement queue
Description
Defines a replacement rule for protecting strings with a placeholder.
Standard rules usage
PlaceholderUnprotectionReplacement
Syntax
PlaceholderUnprotectionReplacement: #«id»
- queue_position: (def) NONE | ROOT | BEFORE #«id» | AFTER #«id»
-
queue_position:
position in the replacement queue
Description
Defines a replacement rule for restoring placeholders to their strings.
Standard rules usage
DeIndentationReplacement
Syntax
DeIndentationReplacement: #«id»
- queue_position: (def) NONE | ROOT | BEFORE #«id» | AFTER #«id»
- positive_flag: (def) NONE | «FLAG_NAME»
- negative_flag: (def) NONE | «FLAG_NAME»
-
queue_position:
position in the replacement queue
-
positive_flag:
name of the flag that must be enabled for the replacement to be applied
-
negative_flag:
name of the flag that must not be enabled for the replacement to be applied
Description
Defines a replacement rule for de-indentation.
Standard rules usage
OrdinaryDictionaryReplacement
Syntax
OrdinaryDictionaryReplacement: #«id»
- queue_position: (def) NONE | ROOT | BEFORE #«id» | AFTER #«id»
- positive_flag: (def) NONE | «FLAG_NAME»
- negative_flag: (def) NONE | «FLAG_NAME»
- apply_mode: (def) SIMULTANEOUS | SEQUENTIAL
* "«pattern»" | '«pattern»' | «pattern»
-->
"«substitute»" | '«substitute»' | «substitute»
[...]
- concluding_replacements: (def) NONE | #«id» [...]
-
queue_position:
position in the replacement queue
-
positive_flag:
name of the flag that must be enabled for the replacement to be applied
-
negative_flag:
name of the flag that must not be enabled for the replacement to be applied
-
apply_mode:
whether the substitutions are to be applied simultaneously or sequentially
-
Patterns and substitutes may be double-quoted, single-quoted, or bare.
-
Patterns and substitutes allow the following interpolations:
| Interpolation key |
Description |
{CMD_VERSION} |
__version__ in _version.py
(currently 6.0.0) |
{CMD_NAME} |
CMD file name, relative to working directory, without extension |
{CMD_BASENAME} |
CMD file name, without path, without extension |
{CLEAN_URL} |
{CMD_NAME}, with {CMD_BASENAME} removed if it equals index |
-
concluding_replacements:
sequence of replacements to be applied after substitution
Description
Defines a replacement rule for a dictionary of ordinary substitutions.
Standard rules usage
RegexDictionaryReplacement
Syntax
RegexDictionaryReplacement: #«id»
- queue_position: (def) NONE | ROOT | BEFORE #«id» | AFTER #«id»
- positive_flag: (def) NONE | «FLAG_NAME»
- negative_flag: (def) NONE | «FLAG_NAME»
* "«pattern»" | '«pattern»' | «pattern»
-->
"«substitute»" | '«substitute»' | «substitute»
[...]
- concluding_replacements: (def) NONE | #«id» [...]
-
queue_position:
position in the replacement queue
-
positive_flag:
name of the flag that must be enabled for the replacement to be applied
-
negative_flag:
name of the flag that must not be enabled for the replacement to be applied
-
apply_mode:
whether the substitutions are to be applied simultaneously or sequentially
-
Patterns and substitutes may be double-quoted, single-quoted, or bare.
-
Patterns and substitutes allow the following interpolations:
| Interpolation key |
Description |
{CMD_VERSION} |
__version__ in _version.py
(currently 6.0.0) |
{CMD_NAME} |
CMD file name, relative to working directory, without extension |
{CMD_BASENAME} |
CMD file name, without path, without extension |
{CLEAN_URL} |
{CMD_NAME}, with {CMD_BASENAME} removed if it equals index |
-
Patterns and substitutes are parsed according to Python regex syntax
with
flags=re.ASCII | re.MULTILINE | re.VERBOSE.
-
concluding_replacements:
sequence of replacements to be applied after substitution
Description
Defines a replacement rule for a dictionary of regex substitutions.
Standard rules usage
FixedDelimitersReplacement
Syntax
FixedDelimitersReplacement: #«id»
- queue_position: (def) NONE | ROOT | BEFORE #«id» | AFTER #«id»
- syntax_type: BLOCK | INLINE (mandatory)
- allowed_flags: (def) NONE | «letter»=«FLAG_NAME» [...]
- opening_delimiter: «string» (mandatory)
- attribute_specifications: (def) NONE | EMPTY | «string»
- prohibited_content: (def) NONE | BLOCKS | ANCHORED_BLOCKS
- content_replacements: (def) NONE | #«id» [...]
- closing_delimiter: «string» (mandatory)
- tag_name: (def) NONE | «name»
- concluding_replacements: (def) NONE | #«id» [...]
-
queue_position:
position in the replacement queue
-
syntax_type:
whether the syntax type is block (delimiters must be on their own lines)
or inline (delimiters may be anywhere)
-
allowed_flags:
flag letters and corresponding flag names
-
opening_delimiter:
the opening delimiter
-
attribute_specifications:
whether, after the opening delimiter,
there may be CMD attribute specifications supplied,
and if so, what the default specification is
-
prohibited_content:
whether block tags or anchored block tags are prohibited
in the content between the opening and closing delimiters
-
content_replacements:
sequence of replacements to be applied
to the content between the opening and closing delimiters
-
closing_delimiter:
the closing delimiter
-
tag_name:
the tag name of the element to be constructed
-
concluding_replacements:
sequence of replacements to be applied after construction of the element
Description
Defines a fixed-delimiters replacement rule.
Standard rules usage
(None)
ExtensibleFenceReplacement
Syntax
ExtensibleFenceReplacement: #«id»
- queue_position: (def) NONE | ROOT | BEFORE #«id» | AFTER #«id»
- syntax_type: BLOCK | INLINE (mandatory)
- allowed_flags: (def) NONE | «letter»=«FLAG_NAME» [...]
- prologue_delimiter: (def) NONE | «string»
- extensible_delimiter: «character_repeated» (mandatory)
- attribute_specifications: (def) NONE | EMPTY | «string»
- prohibited_content: (def) NONE | BLOCKS | ANCHORED_BLOCKS
- content_replacements: (def) NONE | #«id» [...]
- epilogue_delimiter: (def) NONE | «string»
- tag_name: (def) NONE | «name»
- concluding_replacements: (def) NONE | #«id» [...]
-
queue_position:
position in the replacement queue
-
syntax_type:
whether the syntax type is block (delimiters must be on their own lines)
or inline (delimiters may be anywhere)
-
allowed_flags:
flag letters and corresponding flag names
-
prologue_delimiter:
the delimiter that must appear before the opening extensible delimiter
-
extensible_delimiter:
the opening and closing extensible delimiter (a character repeated)
-
attribute_specifications:
whether, after the opening extensible delimiter,
there may be CMD attribute specifications supplied,
and if so, what the default specification is
-
prohibited_content:
whether block tags or anchored block tags are prohibited
in the content between the opening and closing extensible delimiters
-
content_replacements:
sequence of replacements to be applied
to the content between the opening and closing extensible delimiters
-
epilogue_delimiter:
the delimiter that must appear after the closing extensible delimiter
-
tag_name:
the tag name of the element to be constructed
-
concluding_replacements:
sequence of replacements to be applied after construction of the element
Description
Defines a generalised extensible-fence-style replacement rule.
(Inspired by the repeatable backticks of John Gruber's Markdown.)
Standard rules usage
PartitioningReplacement
Syntax
PartitioningReplacement: #«id»
- queue_position: (def) NONE | ROOT | BEFORE #«id» | AFTER #«id»
- starting_pattern: «regex» (mandatory)
- attribute_specifications: (def) NONE | EMPTY | «string»
- content_replacements: (def) NONE | #«id» [...]
- ending_pattern: (def) NONE | «regex»
- tag_name: (def) NONE | «name»
- concluding_replacements: (def) NONE | #«id» [...]
-
queue_position:
position in the replacement queue
-
starting_pattern:
pattern that marks the start of a partition
-
attribute_specifications:
whether, after the starting pattern,
there may be CMD attribute specifications supplied,
and if so, what the default specification is
-
content_replacements:
sequence of replacements to be applied
to the content from the starting pattern up to the ending pattern
-
ending_pattern:
pattern, not consumed, that marks the end of a partition
-
tag_name:
the tag name of the element to be constructed
-
concluding_replacements:
sequence of replacements to be applied after construction of the element
Description
Defines a generalised partitioning replacement rule.
(Does partitioning by consuming everything from a
starting pattern up to but not including an ending pattern.)
Standard rules usage
InlineAssortedDelimitersReplacement
Syntax
InlineAssortedDelimitersReplacement: #«id»
- queue_position: (def) NONE | ROOT | BEFORE #«id» | AFTER #«id»
- delimiter_conversion:
«character» | «character_doubled»=«tag_name» [...] (mandatory)
- attribute_specifications: (def) NONE | EMPTY | «string»
- prohibited_content: (def) NONE | BLOCKS | ANCHORED_BLOCKS
-
queue_position:
position in the replacement queue
-
delimiter_conversion:
a sequence of conversions
from single-character or double-character delimiters
to tag names
-
attribute_specifications:
whether, after each starting delimiter,
there may be CMD attribute specifications supplied,
and if so, what the default specification is
-
prohibited_content:
whether block tags or anchored block tags are prohibited
in the content between the opening and closing delimiters
Description
Defines an inline assorted-delimiters replacement rule.
(A generalisation of the replacement that processes * and **
into <em> and <strong> in Markdown.)
Standard rules usage
HeadingReplacement
Syntax
HeadingReplacement: #«id»
- queue_position: (def) NONE | ROOT | BEFORE #«id» | AFTER #«id»
- attribute_specifications: (def) NONE | EMPTY | «string»
-
queue_position:
position in the replacement queue
-
attribute_specifications:
whether, after the declaring hashes,
there may be CMD attribute specifications supplied,
and if so, what the default specification is
Description
Defines a replacement rule for headings.
(A generalisation of the replacement that processes
ATX headings in Markdown.)
Standard rules usage
ReferenceDefinitionReplacement
Syntax
ReferenceDefinitionReplacement: #«id»
- queue_position: (def) NONE | ROOT | BEFORE #«id» | AFTER #«id»
- attribute_specifications: (def) NONE | EMPTY | «string»
-
queue_position:
position in the replacement queue
-
attribute_specifications:
whether, between the square-bracketed label and the declaring colon,
there may be CMD attribute specifications supplied,
and if so, what the default specification is
Description
Defines a replacement rule for consuming reference definitions.
(A generalisation of the replacement that processes
[«label»]: «uri» "«title»" in Markdown.)
Standard rules usage
SpecifiedImageReplacement
Syntax
SpecifiedImageReplacement: #«id»
- queue_position: (def) NONE | ROOT | BEFORE #«id» | AFTER #«id»
- attribute_specifications: (def) NONE | EMPTY | «string»
- prohibited_content: (def) NONE | BLOCKS | ANCHORED_BLOCKS
-
queue_position:
position in the replacement queue
-
attribute_specifications:
whether, between the square-bracketed alt text
and the round-bracketed URI & title,
there may be CMD attribute specifications supplied,
and if so, what the default specification is
-
prohibited_content:
whether block tags or anchored block tags are prohibited
in the square-bracketed alt text
Description
Defines a replacement rule for specified images.
(A generalisation of the replacement that processes
 in Markdown.)
Standard rules usage
ReferencedImageReplacement
Syntax
ReferencedImageReplacement: #«id»
- queue_position: (def) NONE | ROOT | BEFORE #«id» | AFTER #«id»
- attribute_specifications: (def) NONE | EMPTY | «string»
- prohibited_content: (def) NONE | BLOCKS | ANCHORED_BLOCKS
-
queue_position:
position in the replacement queue
-
attribute_specifications:
whether, after the square-bracketed alt text,
there may be CMD attribute specifications supplied,
and if so, what the default specification is
-
prohibited_content:
whether block tags or anchored block tags are prohibited
in the square-bracketed alt text and the square-bracketed label
Description
Defines a replacement rule for referenced images.
(A generalisation of the replacement that processes
![«alt text»][«label»] in Markdown.)
Standard rules usage
ExplicitLinkReplacement
Syntax
ExplicitLinkReplacement: #«id»
- queue_position: (def) NONE | ROOT | BEFORE #«id» | AFTER #«id»
- allowed_flags: (def) NONE | «letter»=«FLAG_NAME» [...]
- attribute_specifications: (def) NONE | EMPTY | «string»
- content_replacements: (def) NONE | #«id» [...]
- concluding_replacements: (def) NONE | #«id» [...]
-
queue_position:
position in the replacement queue
-
allowed_flags:
flag letters and corresponding flag names
-
attribute_specifications:
whether, after the opening angle bracket,
there may be CMD attribute specifications supplied,
and if so, what the default specification is
-
content_replacements:
sequence of replacements to be applied
to the content between the opening and closing angle brackets
-
concluding_replacements:
sequence of replacements to be applied after construction of the element
Description
Defines a replacement rule for explicit links.
(A generalisation of the replacement that processes
<«uri»> in Markdown.)
Standard rules usage
SpecifiedLinkReplacement
Syntax
SpecifiedLinkReplacement: #«id»
- queue_position: (def) NONE | ROOT | BEFORE #«id» | AFTER #«id»
- attribute_specifications: (def) NONE | EMPTY | «string»
- prohibited_content: (def) NONE | BLOCKS | ANCHORED_BLOCKS
-
queue_position:
position in the replacement queue
-
attribute_specifications:
whether, between the square-bracketed link text
and the round-bracketed URI & title,
there may be CMD attribute specifications supplied,
and if so, what the default specification is
-
prohibited_content:
whether block tags or anchored block tags are prohibited
in the square-bracketed link text
Description
Defines a replacement rule for specified links.
(A generalisation of the replacement that processes
[«link text»](«uri» "«title»") in Markdown.)
Standard rules usage
ReferencedLinkReplacement
Syntax
ReferencedLinkReplacement: #«id»
- queue_position: (def) NONE | ROOT | BEFORE #«id» | AFTER #«id»
- attribute_specifications: (def) NONE | EMPTY | «string»
- prohibited_content: (def) NONE | BLOCKS | ANCHORED_BLOCKS
-
queue_position:
position in the replacement queue
-
attribute_specifications:
whether, after the square-bracketed link text,
there may be CMD attribute specifications supplied,
and if so, what the default specification is
-
prohibited_content:
whether block tags or anchored block tags are prohibited
in the square-bracketed link text and the square-bracketed label
Description
Defines a replacement rule for referenced links.
(A generalisation of the replacement that processes
[«link text»][«label»] in Markdown.)
Standard rules usage
CMD placeholders
There are many instances in which the result of a replacement
should not be altered further by replacements to follow.
To protect a string from further alteration,
it is temporarily replaced by a placeholder
consisting of code points in the main Unicode Private Use Area.
Specifically, the placeholder for a string is of the following form:
«marker»«run_characters»«marker»
-
«marker» is «U+F8FF».
-
«run_characters» are between «U+E000» and «U+E0FF»
each representing a Unicode byte of the string.
It is assumed that the user will not define replacement rules that
tamper with strings of the form
«marker»«run_characters»«marker».
Example
-
Consider the string
£3.
-
Its code points are
U+00A3 and U+0033.
-
The corresponding Unicode bytes are
\xC2\xA3 and \x33.
-
The
«run_characters» are therefore
«U+E0C2»«U+E0A3»«U+E033».
-
The full placeholder is therefore
«U+F8FF»«U+E0C2»«U+E0A3»«U+E033»«U+F8FF».
CMD attribute specifications
When a CMD replacement rule is defined with
attribute_specifications not equal to NONE,
it allows HTML attributes to be specified by CMD attribute specifications
enclosed in curly brackets.
CMD attribute specifications may be of the following forms:
«name»="«quoted value (whitespace allowed)»"
«name»=«bare-value»
#«id»
.«class»
r«rowspan»
c«colspan»
w«width»
h«height»
-«delete-name»
«boolean-name»
In the two forms with an explicit equals sign,
the following abbreviations are allowed for «name»:
-
# for id
-
. for class
-
l for lang
-
r for rowspan
-
c for colspan
-
w for width
-
h for height
-
s for style
Examples
-
Behaviour for the standard rule
#inline-code:
-
CMD:
`{#foo .bar l=en-AU title="baz"} test`
-
HTML:
<code id="foo" class="bar" lang="en-AU" title="baz">test</code>
-
Empty attribute specifications:
-
CMD:
`{} test`
-
HTML:
<code>test</code>
-
Non-
class values will supersede earlier ones:
-
CMD:
`{#1 #2 title=A title=B} test`
-
HTML:
<code id="2" title="B">test</code>
-
class values will accumulate:
-
CMD:
`{.a .b class=c .d} test`
-
HTML:
<code class="a b c d">test</code>
-
Delete
class to reset it:
-
CMD:
`{.a .b -class class=c .d} test`
-
HTML:
<code class="c d">test</code>
Repository links
 Conway-Markdown is dumb.
Conway-Markdown is dumb.